ULF Intro 2 - Role of ULF in Comprehensive Semantic Interpretation
ULFs are underspecified – loosely structured and ambiguous – in several ways. But their surface-like form, and the type structure they encode, make them well-suited to reducing underspecification, both using well-established linguistic principles and machine learning techniques that exploit the distributional properties of language. The image below shows a diagram of the interpretation process from an English sentence to full-fledged Episodic Logic and highlights where ULF fits into it. The structural dependencies in the diagram are shown with solid black arrows and information flow is shown with dashed blue arrows. The backwards arrows exist because the optimal choice at a particular step depends on the overall coherence of the final formula and such coherence information can be used to make decisions in structurally preceding steps. Word sense disambiguation and anaphoric resolution don’t interact with the general structure of the formula so they can be incorporated at any point in the process. The yellow highlighting shows the components of the formula that changed from the previous structurally dependent step in the process.
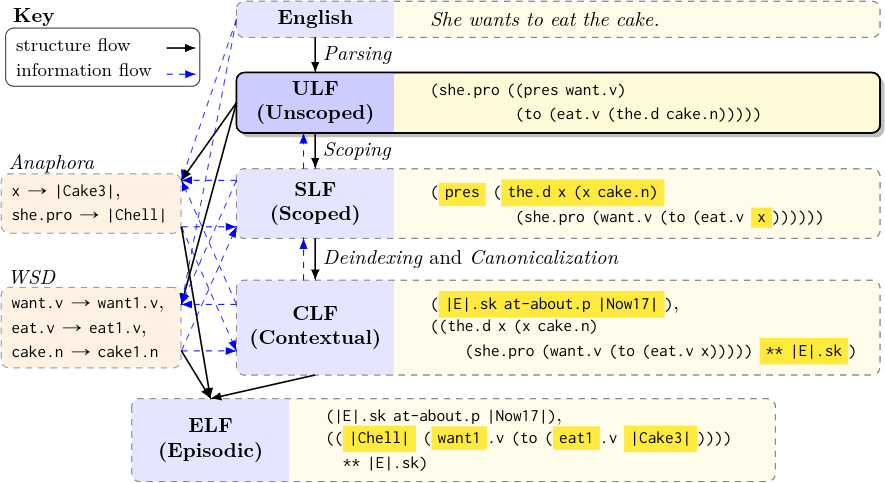
Let’s walk through this diagram. We start of with the sentence
She wants to eat the cake
which is interpreted into the following ULf
(she.pro ((pres want.v) (to (eat.v (the.d cake.n)))))
After tense and determiner scoping (lifting up pres and the.d) it becomes
(pres (the.d (x cake.n) (she.pro (want.v (to (eat.v x))))))
This is then deindexed, Skolemized, and canonicalized (if you don’t understand these terms, read the subsections below) to
(|E|.sk at-about.p |Now17|),
((the.d x (x cake.n) (she.pro (want.v (to (eat.v (the.d cake.n)))))) ** |E|.sk)
|E|.sk is a Skolemized episode variable, which is characterized by the sentence
via the ** operator. Once we’ve resolved who she is and what the cake is,
we can appropriately substitute for them. Say this is the third cake introduced
to the domain of discourse and we know that she is referring to “Chell”. Then
we resolve those conclusions to get
(|E|.sk at-about.p |Now17|),
((|Chell| (want.v (to (eat.v |Cake3|)))) ** |E|.sk)
We can wrap up by performing word sense disambiguation on all the predicates to get
(|E|.sk at-about.p |Now17|),
((|Chell| (want1.v (to (eat1.v |Cake3|)))) ** |E|.sk)
We have developed and applied heuristic algorithms that resolve scope ambiguities and make event structure explicit. Though these algorithms are not sufficiently reliable, they set a baseline for future work. We now discuss each of these resolutions steps in more detail and how ULF supports these later resolutions steps.
Word sense disambiguation (WSD)
Is “bass” a fish or instrument?
(1) I went fishing for some sea bass
(2) The bass line is too weak
One obvious form of underspecification is word sense ambiguity. But while, for
example, (weak.a (plur creature.n)) does not specify which of the dozen
WordNet senses of weak or three senses of creature is intended here, the
type structure is perfectly clear: A predicate modifier is being applied to a
nominal predicate. Certainly standard statistical WSD techniques (Jurafsky & Martin, 2009) can be applied to ULFs, but this should not in general be
done for isolated sentences, since word senses tend to be used consistently
over longer passages. It should be noted that adjectives appearing in
predicative position (e.g., able in able to succeed – (be.v (able.a (to
succeed.v))) or in attributive position (e.g., little in three little
bushes – (three.d (little.a (plur bush.n))) are type-distinct in EL, but
ULF leaves this distinction to further processing, since the semantic type of
an adjective is unambiguous from the way it appears in ULF.
Predicate adicity
How many arguments does a predicate take?
A slightly subtler issue is the adicity of predicates. We do not assume unique
adicity of word-derived predicates such as run.v, since such predicates can
have intransitive, simple transitive and other variants (e.g., run quickly
vs. run an experiment). But adicity of a predicate in ULF is always clear
from the syntactic context in which it has been placed – we know that it has
all its arguments in place, forming a truth-valued formula, when an argument
(the “subject”) is placed on its left, as in English. It is for this reason
that arguments that are implicit in the surface sentence are introduced in
ULFs, such as in example 1 from ULF Intro 1,
Could you dial for me?
(((pres could.aux-v) you.pro (dial.v {ref1}.pro
(adv-a (for.p me.pro)))) ?)
In this example, {ref1}.pro is not in the surface sentence, but a known
necessary argument of dial for this sentence to make sense.
Scope ambiguity
Every dog sees a bone
Does every dog see the same bone?
The sentence above has two possible relative scopings of the two determiners, every and a, which give distinct readings of the sentence. Either, there can be a bone with respect to each of every dog as in the following
(every.d x: (x dog.n) (a.d y: (y bone.n) (x ((pres see.v) y))))
or there could be a bone that is seen by every dog which would be resolved as below.
(a.d y: (y bone.n) (every.d x: (x dog.n) (x ((pres see.v) y))))
This sort of ambiguity can arise from the three types of unscoped elements in
ULF, which are determiner phrases derived from noun phrases (such as very
few people and the Earth – ((nquan (very.mod-a few.a)) (plur person.n)
and (the.d |Earth|.n), respectively), the tense operators pres and past,
and the coordinators and.cc, or.cc and some variants of these. The
positions they can “float” to in postprocessing are always pre-sentential, and
determiner phrases leave behind a variable (e.g. x and y in the motivating
example about the dog and the bone above) that is then bound at the sentential
level. This view of scope ambiguity was first developed in (Schubert & Pelletier, 1982) and subsequently elaborated in (Hurum & Schubert, 1986) and
reiterated in various publications by Hwang and Schubert.
The accessible positions are constrained by certain restrictions well-known in linguistics. For example, in the sentence
“Browder … claims that every oligarch in Russia was forced to give Putin half of his wealth”,
there is no wide-scope reading of every, to the effect “For every oligarch in Russia, Browder claims … etc.”; the subordinate clause is a “scope island” for strong quantifiers like every (as well as for tense). The ULF allows exploitation of such structural constraints, since it still reflects the surface syntax. Firm linguistic constraints still leave open multiple scoping possibilities, and many factors influence preferred choices, with surface form (e.g., surface ordering) playing a prominent role (Manshadi et al., 2013). So again the proximity of ULF to surface syntax will be helpful in applying ML techniques to determining preferred scopings.
Anaphora
John saw Bob and told him he had to go home
Who are “him” and “he”?
Another important aspect of disambiguation is coreference resolution. Again there are important linguistic constraints (“binding constraints”) in this task. For example, in “John said that he was robbed”, he can refer to John; but this is not possible in “He said that John was robbed”, because in the latter, he C-commands John, i.e., in the phrase structure of the sentence, it is a sibling of an ancestor of John. ULF preserves this structure, allowing use of such constraints. In the ULF for these sentences,
(|John| ((past say.v) (that (he.pro (past (pasv rob.v))))))
(he.pro ((past say.v) (that (|John| (past (pasv rob.v))))))
we see that in the former formula, |John| is the sibling of the verb
phrase ((past say.v) (that (he.pro (past (pasv rob.v))))), which
indeed is an ancestor of he.pro. Similarly, in the latter formula,
we get the opposite since he.pro and |John| are in opposite positions.
Preservation of structure also allows application of ML techniques (Poesio et al., 2016), but again this should be done over passages, not individual sentences, since coreference “chains” can span many sentences. When coreference relations have been established as far as possible and operators have been scoped, the resulting LFs are quite close in form to first-order logic, except for incorporating the additional expressive devices (generalized quantifiers, modification, attitudes, etc.) that we have already mentioned and illustrated. In our writings we call this the indexical logical form, or ILF. ILF doesn’t appear in the intepretation process diagram due to the particular decomposition of steps we show in the diagram. The anaphora resolution is shown as a structurally independent step from the core structural changes. However, it is required for the final EL interpretation.
Event/situation structure
What are the events in the sentence and how do they relate?
The critical aspect of episodic logical form is event/situation structure. Much of the past work in EL has been concerned with the principles of de-indexing, i.e., making events and situations – episodes in our terminology – explicit (Hwang, 1992; Hwang & Schubert, 1994; Schubert, 2000). The relationship to Davidsonian event semantics and Reichenbachian tense-aspect theory is explained in these references. Their compositional approach to tense-aspect processing leads to construction of a so-called tense tree, and yields multiple, related reference events for sentences such as “By 8pm tonight, all the employees will have been working for 15 hours straight”. The compositional constuction and use of tense-trees is possible only if the logical form being processed reflects the original clausal structure – as ULF indeed does. This step is merged with the following, canonicalization step in the diagram above.
The EL approach to the semantics of tense, aspect, and temporal adverbials differs
from the traditional Davidsonian approach in that it associates episodes not
only with atomic predications, but also with negated, quantified, and other
complex sentences. For example, in ELF there is an explicit referent available
for the phrase this situation in sentence pairs such as “No rain fell for
two months. *This situation* led to crop failures”, or “Every theater
patron was trying to exit through the same door. *This situation* led to
disaster”. In addition, we regard perfect and progressive aspect, via
operators perf and prog, together with the tense operators pres and
past and modal auxiliary will.aux-s, as contributing to temporal
structure compositionally, rather than by enumeration of possible
tense-aspect combinations. The compositional process is mediated by tense
trees systematically determined by ULF structure. The process deposits, and
makes reference to, episode tokens at tense tree nodes, relating the various
times/episodes referred to in sentences such as By 8pm tonight, all the
employees will have been working for 15 hours straight”. Details are
provided in the publications above, especially (Hwang & Schubert, 1994).
Canonicalization
Finally, canonicalization of ELF into “minimal” propositions, with top-level Skolemization (and occasionally \(\lambda\)-conversions), is straightforward. Some complex examples are shown in prior publications (Schubert & Hwang, 2000; Schubert, 2014; Schubert, 2016).
When episodes have been made explicit (and optionally, canonicalized), the result is episodic logical form (ELF); i.e., we have sentences of Episodic Logic, as described in our previously cited publications. These can be employed in our Epilog inference engine for reasoning that combines linguistic semantic content with world knowledge. A variety of complex Epilog inferences are reported in (Schubert, 2013), and (Morbini & Schubert, 2011) contained examples of self-aware metareasoning. Further in the past, Epilog reasoned about snippets from the Little Red Riding Hood story: If the wolf tries to eat LRRH when there are woodcutters nearby, what is likely to happen?”; answer chain: The wolf would attack and try to subdue LRRH; this would be noisy; the woodcutters would notice, and see that a child is being attacked; that is a wicked act, and they would rush to help her, and punish or kill the wolf (Hwang, 1992; Schubert & Hwang, 2000). However, the scale of such world-knowledge-dependent reasoning has been limited by the difficulty of acquiring large amounts of inference-enabling knowledge. (The largest experiments, showing the competitiveness of Epilog against state-of-the art theorem provers were limited to formulas of first-order logic (Morbini & Schubert, 2009).) In the proposed work we therefore focus on inferences that are important but not heavily dependent on world knowledge.
The potential of EL reasoning has been extensively demonstrated, making the prospect of effectively mapping language to EL an attractive one. The most complete [language \(\rightarrow\) reasoning] system built so far (2012-14) was a system for interpreting captions of family photos (e.g., Alice, with her two grandmothers at her graduation party), then aligning the caption-derived knowledge with image-derived data about individuals’ apparent age, gender, hair color, eye-wear, etc., merging the knowledge, and then inferentially answering questions (Who graduated?). Unpublished reports (to ONR) on this work exist, but further development has been hampered by difficulties in obtaining large collections of captioned family photos for scaling up.
Thus ULFs comprise a “primal” logical form whose resemblance to phrase structure and whose constraints on semantic types provide a basis for the multi-faceted requirements of deriving less ambiguous, nonindexical, canonical LFs suitable for reasoning. However, as we have pointed out, ULFs are themselves inference-enabling, and this will be important for our evaluation plan.
References
- Poesio, M., Stuckardt, R., & Versley, Y. (Eds.). (2016). Anaphora Resolution - Algorithms, Resources, and Apcations. Springer. https://doi.org/10.1007/978-3-662-47909-4
- Hurum, S., & Schubert, L. (1986). Two types of quantifier scoping. Proc. 6th Can. Conf. on Artificial Intelligence (AI-86), 19–43.
- Hwang, C. H. (1992). A logical approach to narrative understanding [PhD thesis]. University of Alberta.
- Hwang, C. H., & Schubert, L. K. (1994). Interpreting Tense, Aspect and Time Adverbials: A Compositional, Unified Approach. Proceedings of the First International Conference on Temporal Logic, 238–264.
- Jurafsky, D., & Martin, J. H. (2009). Speech and language processing (2nd ed.). Pearson/Prentice Hall.
- Manshadi, M., Gildea, D., & Allen, J. (2013). Plurality, Negation, and Quantification:Towards Comprehensive Quantifier Scope Disambiguation. Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 64–72.
- Morbini, F., & Schubert, L. (2009, June). Evaluation of Epilog: A reasoner for Episodic Logic. Proceedings of the Ninth International Symposium On Logical Formalizations of Commonsense Reasoning.
- Morbini, F., & Schubert, L. (2011). Metareasoning as an Integral Part of Commonsense and Autocognitive Reasoning. In M. T. Cox & A. Raja (Eds.), Metareasoning: Thinking about thinking. MIT Press.
- Schubert, L. K., & Pelletier, F. J. (1982). From English to logic: Context-free computation of ’conventional’ logical translations. Am. J. of Computational Linguistics 8 [Now Computational Linguistics], 8, 26–44.
- Schubert, L. (2013). NLog-like inference and commonsense reasoning. In A. Zaenen, V. de Paiva, & C. Condoravdi (Eds.), Perspees on Semantic Representations for Textual Inference, special issue of Linguistic Issues in Language Technology (LiLT 9) (Vol. 9, pp. 1–26).
- Schubert, L. (2014). From Treebank Parses to Episodic Logic and Commonsense Inference. Proceedings of the ACL 2014 Workshop on Semantic Parsing, 55–60.
- Schubert, L. (2016). Semantic Representation. Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, 4132–4138.
- Schubert, L. K. (2000). The Situations We Talk About. In J. Minker (Ed.), Logic-based Artificial Intelligence (pp. 407–439). Kluwer Academic Publishers.
- Schubert, L. K., & Hwang, C. H. (2000). In L. M. Iwańska & S. C. Shapiro (Eds.), Natural Language Processing and Knowledgeepresentation (pp. 111–174). MIT Press.