Towards Cost-effective
On-demand Continuous Media Service: A Peer-to-Peer Approach
Course Project Proposal for
CS590N
Fall 2002
By
Yicheng Tu and Shan Lei
1. Problem statement
The
recent development of broadband networking technology has made deployment of
continuous media (CM) service throughout the Internet possible. With CM service
becoming feasible, attractive applications such as on-line entertainment video
delivery, digital library, and telemedicine systems can be built on top.
Unlike traditional Internet file service, CM
requires data of interest being delivered to clients
in a streaming manner. That is, each part of the media has to be transmitted
and arrive at the client side before a deadline. This brings tremendous
challenges to the design of CM servers in a best-effort delivery networking
environment, such as the Internet. Generally, the untimely transmission of
media fragments becomes worse when more requests are received and the
communication channel gets congested. The current solution to this problem is
to replicate media data on different sites on the Internet to avoid any
individual locations being swamped by requests. One popular practice for media
replication is to deploy Content Distribution Networks (CDN) on the edge of the
Internet. Each of these CDN servers holds a copy of all media files and is
responsible for serving requests from its neighboring area.
However, the cost of constructing and maintaining
a CDN is extremely high considering the massive CPU power, storage space and
output bandwidth each CDN server has to possess. Among the computing resources
in a CDN-based CM service, the output bandwidth was found to be the
bottlenecking factor under a flash crowd situation [1]. For example, a server with
a T3 line connected to it has a maximum bandwidth of 45Mbps. When the media
streams being serviced are MPEG-1 videos with an average bitrate
of 1.5Mbps, only 30 concurrent sessions can be supported. The peak number of
sessions that need to be serviced simultaneously could be in the order of
thousands or even higher. To make the whole system scalable in terms of number
of concurrent requests it handles without swamping any server, a large number
of such servers have to be deployed in the Internet. The primary concern of
this research is to find an inexpensive way to alleviate the traffic load for
media streaming on the servers in a CM service infrastructure.
Our approach to solve the above problem is
motivated by the emerging new concept of peer-to-peer computing [2, 3, 4]. In a peer-to-peer system, there is no
centralized entity controlling the behaviors of each peer. Instead, each peer
contributes its share of resources and cooperates with other peers using some
predefined rules for communication and synchronization. In the context of media
streaming, a well-organized community of clients can help relieve the service
load of CM servers by taking over some of the streaming tasks that could only
be accomplished by server machines in a CDN-based scheme. The basic idea is to
let clients that obtained a media object act as streaming servers for following
requests to that media object. One of the nice features of peer-to-peer
community is that its total capacity grows when the content it manages becomes more
popular [5]. And this is the most important difference between peer-to-peer and
centralized strategy.
With the promising prospect of applying peer-to-peer in CM service, there are some problems we have to face, too. First of all, peers are heterogeneous in the storage capacity and out-bound bandwidth they can contribute. Any attempt to build peer-to-peer streaming infrastructure has to take this into account. A specific problem is how to avoid swamping a supplying peer. Meanwhile, smart replacement strategies have to be studied due to the limited storage a peer uses to cache video objects. Secondly, peers are heterogeneous in the duration of their commitment to the community. This come-and-go behavior makes a peer-to-peer system intrinsically dynamic. How to minimize the effects of this behavior is another research problem we need to address. On the other hand, the scenarios of CM service could also be complex. Besides the number of requests we have discussed above, the number of media objects, access patterns to the same object, Quality-of-Service (QoS) requirements on streaming are all concerns in the design of a CM service. These will be further discussed in section 2 of this proposal. Our proposed CM service infrastructure will address as many of these factors as possible. Thus, our work here can be regarded as complements to other people’s work, which will be presented in section 3. As we can see, the idea of peer-to-peer streaming is not new. However, we propose some different methods that we believe are improvements to those in previous work. Section 4 is composed as a sketch of our proposed solution. Finally, a brief schedule is listed in section 5.
2. Research issues.
To build up an Internet media streaming infrastructure, we have to face challenges in a number of research areas. These include: media coding, QoS control, media distribution, real-time system design for streaming servers, and streaming protocols [6]. Our proposed peer-to-peer streaming architecture brings up research topics that fall into the areas of media distribution and streaming protocols. The computing resources we consider in this study are CPU, storage, and bandwidth. We focus on the bandwidth throughout this research with some attention paid to CPU and storage in a couple of smaller problems. The rest of this section is discussion on some of the specific problems we identified.
2.1 System architecture
A hybrid media-streaming architecture that combines CDN and a peer-to-peer community is proposed and analyzed in [7]. It is also shown in the paper that the CDN server’s streaming load is alleviated by the group of clients that act as supplying peers. Beyond a certain point, the servers can even handoff the whole streaming task to the peer-to-peer community. Our streaming architecture is based on this hybrid system. However, modifications and more detailed policies will be applied to their model to make it closer to a real-world system. These changes include the number of files in a peer and the whole system, the role of CDN servers, use of directory server, and contribution policy for peers.
When the design of system architecture is finished, the next thing is to study the dynamics of the system. Simulation tools can be used for this purpose. We believe the results of the simulation may provide us with feedback information that can be used to fine-tune the controllable factors of the original design, sometimes even interesting activities that are worth more research efforts.
2.2 Indexing of peers and media objects
An Internet streaming system may have hundreds of thousands or even millions of users as well as a large number of media objects. Keeping a directory of the availability and updated status of these users (peers) and media files that supports efficient update and search is not a trivial task. Although this is always a doable job, we are aiming at minimizing the computational complexity of the directory management. Specifically, our directory server has to keep the paired information of (Peer, Object), where Peer is a client that’s willing to serve as a supplying peer and Object is the ID of a media file Peer holds. Basic operations on these paired data will be:
· Insert(Peer p, Object o): insert the pair (p, o) into the directory;
· Delete(Peer p, Object o): find and delete the pair (p, o) from the directory;
· Leave(Peer p): p leaves the community, delete all data points whose Peer field equals p;
· Join(Peer p): peer p joins the community;
· Find(Object o): Find all the peers that hold Object o.
What makes the bookkeeping of this information in the directory more complicated is the possibly frequent failure of peers. Peer failure is generally not an event that can be instantly detected by the directory server. Instead, we need to schedule a heartbeat message sent from the directory server to each active peer at a fixed time interval. Unresponsive peers are regarded as dead and deleted from the directory. The heartbeat messages could occupy a significant share of the server’s bandwidth if the number of peers is large. Our heartbeat policy should limit the use of server bandwidth while achieving high sensitivity to peer failures.
2.3 Failure-resistant peer-to-peer streaming
In a peer-to-peer streaming system, we cannot make any assumption on the contribution of a single peer, especially its bandwidth. We name this the rule of limited contribution. Chances are peer-to-peer streaming is always of a many-to-one style due to the limited bandwidth each peer can provide. The problem is, in a dynamic environment where peers have no fixed commitment period, how we can protect all the on-going streaming sessions from the leave or failure of their supplying peers. One solution used by the CoopNet project [8] is called Multiple Description Coding (MDC). What MDC does is to transcode the original media stream into m substreams (descriptions), each of which carries partial information of the media. Any k (k < m) substreams can be multiplexed to support a viewable media playback session with degraded QoS. MDC solves the problem of peer failure during a streaming session but it brings big overhead. The compression rate of MDC is very low and it requires the supplying peers to do online transcoding. This can be translated into higher resource consumption in the peers and a violation of the limited contribution rule. In our research, we will develop a strategy that supports smooth many-to-one streaming without introducing extra load to the peers and severe degradation of QoS. We propose the policy of spare channel replacement that utilizes idle peers as replacements to the failed ones. This is based on the hypothesis that in our dynamic peer-to-peer streaming system, with high probability, we can find more peers capable of streaming a video object than needed. To show the validity of spare channel replacement, a well-designed real-time media transmission protocol with the capability of failure detection, rate control, dynamic resource switching is a must.
2.4 Media replacement policy in a peer
Again the limited contribution rule implies a peer may only provide a limited share of its disk space. When a new media is obtained and the space is full, the peer has to decide which one(s) to discard. A smart replacement policy will increase the total hit rate of all the cached media files in the peer-to-peer community. We will work out a policy that takes the query rate of each media object into account and compare the performance of our policy with that of other generic cache replacement rules.
3. Related work
A good review of Internet video streaming can be found in [6]. The key areas of video streaming are identified in the review and thorough discussions are made on the major approaches and mechanisms within these areas. Future research directions are also pointed out. [2] and [3] introduced the general philosophy of peer-to-peer computing, current research efforts, and applications of peer-to-peer systems. The candidate systems that can be used as substrates of our peer-to-peer self-organization mechanism include Pastry[9], Chord[10], and CAN[11].
In the context of peer-to-peer streaming, both the CoopNet project of Microsoft [12] and the ZIGZAG prototype
[13] of
Work on hybrid streaming architecture [7] that combines CDN and peer-to-peer is directly related to the system design in this research. In some sense, this proposal is directed to an extension of the model proposed in [7]. Mathematical analysis as well as simulation experiments showed that the peer-to-peer community significantly lowered the streaming load of the CDN servers. Based on their model, the contribution of our research would be to study the system behavior by putting more details into the model and provide solutions to problems discussed in Section 2 that are not addressed in [7].
An earlier work [5] to [7] developed an algorithm that assigns media segments to different supplying peers and a protocol for peer admission. Another research project by Nguyen and Zakhor [19] is more closely related to our research in the aspect of streaming protocol development. In this paper, they presented an RTP-like protocol that does rate control and packet synchronization. A packet partition mechanism used for the supplying peers to determine which packets to send is also assimilated into the design of their protocol. From [20] we can get access to open-source streaming software releases that are built upon RTP/RTSP. [21] is the original paper that describes the basic operations and performance analysis of the k-d tree data structure.
4. Our
approach
4.1 System architecture
We
propose a continuous media streaming infrastructure (Figure 1) that is close to
the hybrid model in [7]. We view the users of the CM service interacting with
the system through a client side program that sends queries to a centralized
cluster of database servers. The first step for a user request is to locate
media objects of interest. This typically involves keyword or content-based
search that can be accomplished by the database server in a very efficient way.
The scalability of the database system itself is high as compared to the CDN
for streaming purposes. The next layer is the CDN as usual and the
participating clients (peers) as another layer. However, we tend to make the
CDN and the peer-to-peer community as a whole streaming
network instead of have one CDN server organize a local group of peers.
Thus, the directory maintenance of peer/media information is pushed up to the
database server clusters (From now on, this centralized server cluster is
called the “directory server”). All the CDN servers will only be responsible
for streaming when the requested media cannot be serviced through the
peer-to-peer network. Each CDN server is supposed to hold a copy of all media
files.
We
follow the rule of limited contribution in [7] to let each participating
peer announce the bandwidth and storage it can provide. A little modification
here is that we don’t specify how many concurrent sessions a peer can accept.
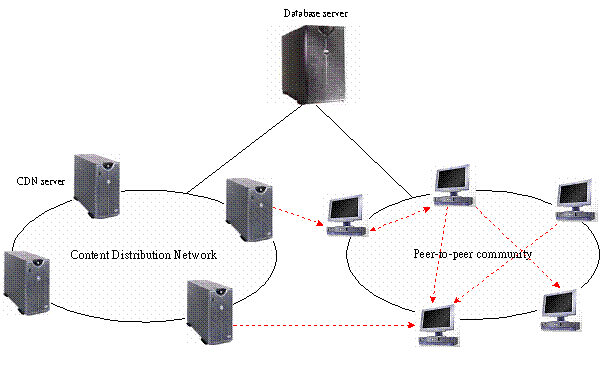 Figure 1. System architecture of the
hybrid CM service
Figure 1. System architecture of the
hybrid CM service
Simulation experiments have to be done to study the system dynamics. We want to get an idea of how the system behaves in the following aspects: 1). Does our system show any benefit in contrast to a CDN-only solution; 2). When does the system start to show the benefit? 3). The load distribution of all the peers; 4). How many peers are available when a streaming request is imposed? We use request reject rate and the mean load of CDN servers as indications of the “benefit”.
4.2
Directory
service
Intuitively,
a 2-d tree is a good candidate data structure for storing the paired directory
entries mentioned in section 2.2. This is because both Peer and Object
could be used as search keys. A 2-d tree provides efficient (O(logN) where N is the total number of tree nodes) search on
both dimensions and the range query operations such as Find(Object o) is
also fast. We need to augment a general 2-d tree, though. For example, the
biggest problem of k-d is that it could be unbalanced. We will try to find an
online method to balance the tree.
As
to the heartbeat policy, for now, we decided to deploy it on the directory
server (details in Section 2.2). The disadvantage of this method is that the
server is bound to use a significant share of its bandwidth for the regular
heartbeat messages. An alternative to this is to build up a community for the
clients using peer-to-peer naming/routing strategies such as those in Pastry
and Chord. The point is: we depend on each peer in the community to keep track
of a small set of other peers by sending them heartbeat messages. For examples,
a Pastry node can ping all (or some) nodes in its leaf set or neighbor set.
When failure is detected, a report is sent to the directory server. The unusual
thing here is that we never need to use the Pastry routing table to locate any
other nodes. We will compare costs for both heartbeating
strategies.
4.3
Spare channel
replacement
Somehow,
this strategy depends on the results of system experiments mentioned in 4.1.
That is: the possibility of finding spare channels is high. This could be true
because the CDN servers can be used when no other peers are available at all.
The system capacity is not decreasing even though the CDN servers are taken as
replacements since some of the bandwidth is provided by other surviving peers.
We
plan to implement a media server and player for MPEG videos based on the
protocols proposed in [19]. Efforts on this problem should be concentrated on
how to achieve smooth switching of video resources. This can also be done in
collaboration with other groups in the class.
4.4
Media
replacement
The
basic principle of media replacement is the same as data replication according
to the access rate. For any media object, we can calculate the targeted number
of replica KT based on the access rate λ .
Then the priority coefficient of keeping this object is given as KT/KC
where KC is the number of current replica. The media object
with the lowest priority will be discarded. The information needed for calculating KT
and KC can be easily maintained by the directory server.
We
can always feed this replacement policy into our simulation setup and make
comparisons between this policy and generic ones such as FIFO, LFU, and LRU.
5. Schedule
Directory
service algorithms formalized before
System
simulation strategies and tools set by
Streaming
software built by
Reference
[1] V.
N. Padmanabhan and K. Sripanidkulchai. The Case for
Cooperative Networking. Proceedings of the First International
Workshop on Peer-to-Peer Systems (IPTPS), March 2002
[2] D. S. Milojicic,
V. Kalogeraki, R. Lukose,
K. Nagaraja, J. Pruyne, B. Rihard, S. Rollins, and Z. Xu. Peer-to-Peer Computing. HP Labs Technical Report
HPL-2002-57.
[3] A. Rowstron
and P. Druschel, Pastry: Scalable, decentralized
object location and routing for large-scale peer-to-peer systems. ACM/IFIP Middleware 2001.
[4] J. Crowcroft
and
[5]
D. Xu, M. Hefeeda,
S. Hambrusch, and B. Bhargava.
On Peer-to-Peer Media
Streaming. Proceedings of IEEE ICDCS 2002, July 2002.
[6]
D. Wu, Y. T. Hou, W. Zhu, Y-Q. Zhang, and J. M. Peha (2001). Streaming Video over the Internet: Approaches and Directions.
IEEE Transactions on Circuits and Systems for Video
Technology. Vol. 11, No. 1, February 2001.
[7]
D. Xu, H-K. Chai, C. Rosenburg,
and S. Kulkarni (2003). Analysis of a Hybrid Architecture for Cost-Effective Streaming Media
Distribution. Proc. of SPIE/ACM Conf. on Multimedia Computing and Networking
(MMCN 2003),
[8] V. N. Padmanabhan,
H. J. Wang, P. A. Chou, and K. Sripanidkulchai. Distributing Streaming Media Content Using Cooperative Networking. ACM NOSSDAV, May 2002.
[9]
A. Rowstron and P. Druschel. Pastry: Scalable, Distributed Object Location and
Routing for Large-scale Peer-to-peer Systems. In International
Conference on Distributed Systems Platforms (Middleware), November 2001.
[10]
[11]
S. Ratnasamy, P. Francis, M. Handley, R. Karp, and S.
Shenker.
A Scalable Content-Addressable Network. In Proceedings of the ACM SIGCOMM ‘01,
[12]
http://research.microsoft.com/~padmanab/projects/CoopNet
[13] D. A. Tran, K. A. Hua, and T. T. Do. ZIGZAG: An Efficient Peer-to-Peer Scheme
for Media Streaming. Technical report of University if
[14]
Y. Wang, M. T. Orchard, and A. R. Reibman. Optimal Pairwise
Correlating transforms for Multiple Description Coding. In Proceedings
of International Conference of Image Processing,
[15] J. Apostolopoulos, T. Wong, W. Tan, and S. Wee. On Multiple Descrption Streaming with
Content Delivery Networks. In Proceedings of IEEE
INFOCOMM 2002, June 2002.
[16]
H. Deshpande, M. Bawa, and
H. Garcia-Molina. Streaming Live Media over a Peer-to-Peer Network. Technical
Report 2001-31,
[17]
http://www.allcast.com
[18]
http://www.vtrails.com
[19] T. Nguyen and A. Zakhor. Distributed Video Streaming over Internet. In Proceedings of SPIE/ACM MMCN 2002, January 2002.
[20]
http://www.live.com
[21] J. L. Bentley. Multidimensional Binary Search Trees Used for Associative
Searching. Communications of the ACM. Vol 18.
No. 9, 1975